
Real-time Neural Radiance Caching for Path Tracing
關鍵字:AI, Path Tracing, 圖學
論文作者: Thomas Müller, Fabrice Rousselle, Jan Novák, Alex Keller
時間:2021 / 07 / 21
Direct vs Global Illumination
在開始談這篇論文之前,首先提一下 Direct illumination 與 Global illumination 的差異。Direct 光照又稱 local 光照,意味著光從光源打到物體後就不會再繼續往下打。而 glocal 光照則是 direct + indirect,也就是光會在場景內 bounce 非常多次 (理論上是無限次)。
從圖中可看到,右邊的 Global illumination 相較於左邊的 local 多了很多光反射的細節,更加接近真實。那這篇論文想達到的效果就是右邊 global illumination 的效果。目前要達到這類型的光照效果是不可能的,由於涉及了光的多次反射、折射、散射等,目前的硬體無法實時的將結果運算出來。

Radiance vs Irradiance
因此本文作者提出了透過 AI 去對 Radiance 做快取,讓 AI 自己學習不同位置的光能量,減少運算次數,藉此達到 real time。
那麼問題來了,甚麼是 Radiance,甚麼是 Irradiance?
這是 wikipedia 對於 Radiance 的解釋,那簡單翻譯一下,Radiance 為光的能量,Irradiance 是相機端接收到的光能量。
光源的輻射率,是描述非點光源時光源單位面積強度的物理量,
定義為在指定方向上的單位立體角和垂直此方向的單位面積上的輻射通量,記為 L。
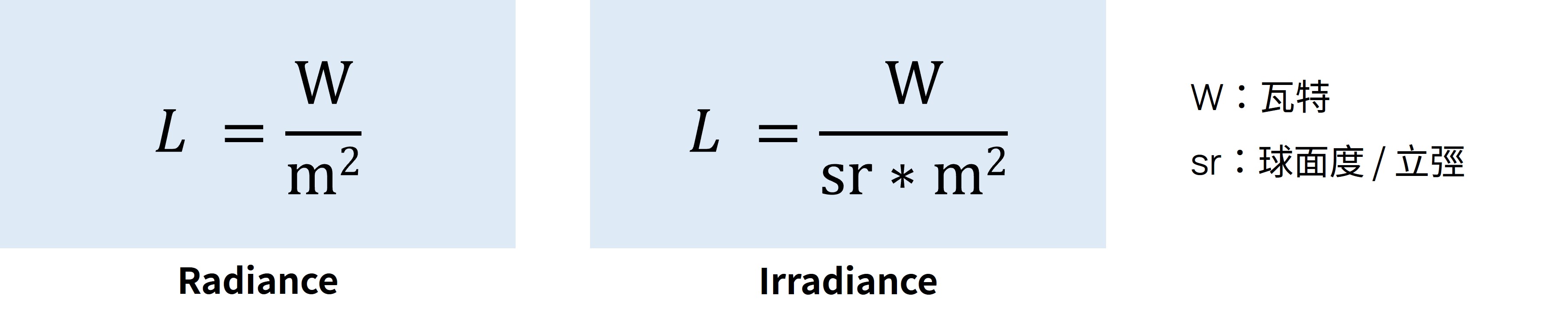
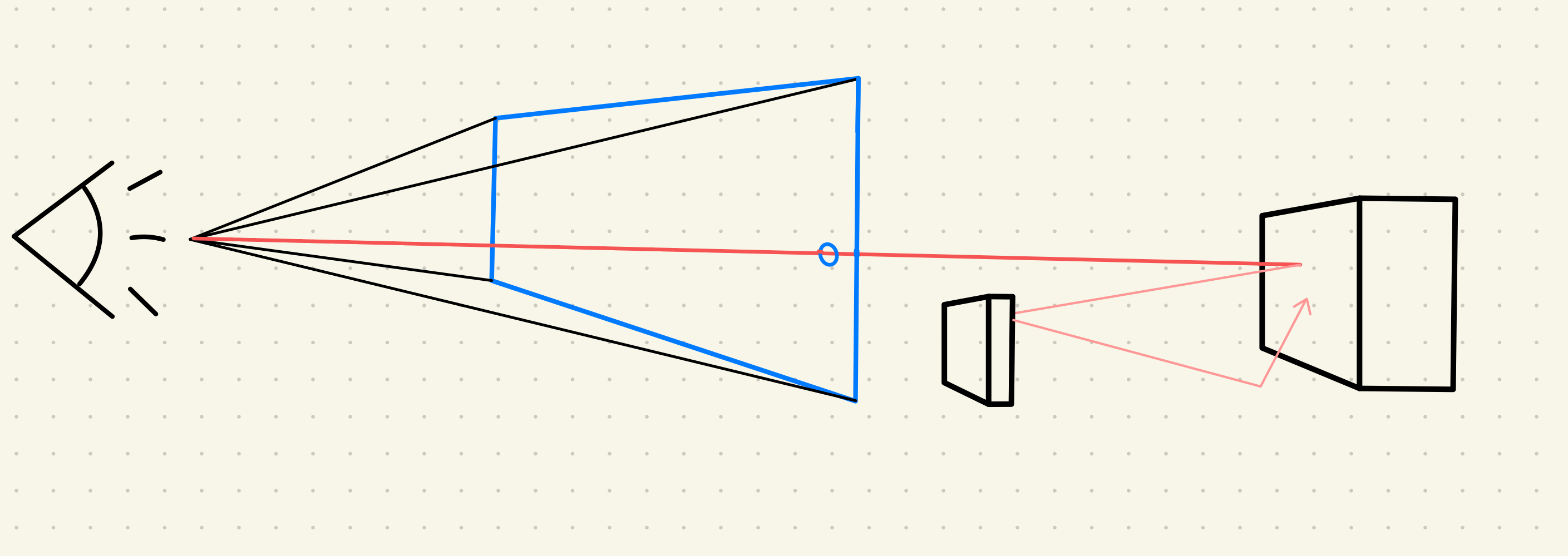
以往就有人針對 Irradiance 做快取,來加速運算。
當光打到一個位置後,計算出這個點收到的光能量,並存入快取。等快取的數量夠多時,就可以依據快取內的光能量,對其他位置做內插。這樣就不用將整個螢幕內的光能量都計算出來,藉此減少運算時間。
但這樣會遇到幾個問題:
- 光只能是 Smooth 的
例如因為做內插,所以光是建立在 smooth 的前提之上,所以遇到邊緣就會GG。 - 場景不能動態
做快取這件事情也需要花不少時間與記憶體,因此通常是透過 precomputation 來達到加速的效果,那既然是預先運算,自然場景不能是動態的。 - 只支援 Diffuse 材質
- Light leakage 問題
在角落位置會出現漏光的問題,如下圖所示。因為在角落部分,對周圍的快取做內插時,會抓到隔壁區域的光,造成漏光。

圖片引用自 blenderartists.org
Neural Radiance Caching
那麼回過頭來看,這篇論文如何克服以上問題?以及他的終極目的?
目的:
以 Real-time 做 path tracing,並且相較於其他方法要有更少的噪點。
貢獻:
- 提出了 Neural Radiance Caching,由神經網路替代記憶體 Cache。
- Efficient online self-Training
以下是作者的 demo video,可以搭配觀看。 https://d1qx31qr3h6wln.cloudfront.net/publications/nrc-video.mp4
之所以會需要用到 AI 來做快取的原因在於,如果只是單純地用記憶體或是硬碟做 Radiance caching,會很耗記憶體與頻寬,且由於場景是動態的,要如何辨別快取內的資料是否需要做更新也是個大問題。畢竟如果不做更新,可能會遇到一個 ray 打出去,以前打到的地方光被遮蔽,因此光能量很低;但當場景更動後,這個位置可能光已不被遮蔽,但舊的快取資料卻還是光被遮蔽時的資訊。 這邊作者用了一個很特別的方式來訓練這個 Cache,不同於一般熟悉的 AI 訓練流程:
- 收集資料
- 訓練
- 用訓練好的模型來預測
作者透過在 Render 過程中動態訓練 AI 模型並預測,來更新 cache。這麼做的好處在於可以讓動態的場景有效率的更新快取資料,pre-train 資料僅對於單一場景有用,從室內換到室外這 AI 可能就死給你看了。
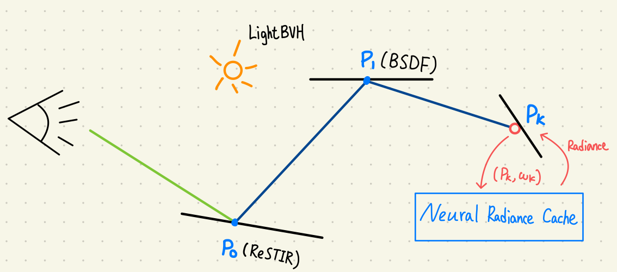
ReSTIR
容我在多嘴提一下論文的背景資料,前面提到 Global illumination 是第一層的 direct lighting + indirect lighting。而 ReSTIR 這東西主要是在改善 direct lighting 的效率,那作者的 NRC 在第一層的 ray 計算就是透過 ReSTIR 來計算,因此後面如果有對比 Nerual Radiance Cache 啟用與否的效果,就是對比 ReSTIR VS ReSTIR + Neural Radiace Cache,有興趣可以去看看這篇論文。

Caching 機制
好終於回歸正題了,那麼 NRC 是怎麼做快取的?以及他快取的究竟是甚麼東西。
首先 NRC 與一般的 path tracing 很類似,從眼睛往視角方向依據螢幕像素打 ray,打到物件後,讓 ray 散開往下彈出去。等到彈得夠多次就能找到這個 pixel 最接近真實的顏色。
 而打到物件後,這顏色的決定就得依據傳說中的 rendering equation:
而打到物件後,這顏色的決定就得依據傳說中的 rendering equation:

在這噁心的公式當中,Scatter radiance 是運算起來最麻煩的一個,它代表著光在點 $x$ 撞到物件後,往 $w$ 方向散出的能量,也是作者想要快取的東西。
\[L_s(x, w) := \int_{S^2}{f_s(x, w, w_i) L_i(x,w_i) | cos\theta_i | dw_i}\]那麼快取運作的機制是這樣的,當從 Camera 打出 ray 之後,在場景中反彈個幾下後,將這條 ray 直接中止。把擊中的點 x 與 ray 的方向餵給 cache,並從 cache 獲得這個點所對應的顏色。
何時中止 ray?
那麼要何時把這條 Ray 給中止呢?就是當這光能量的 aera spread 已經足夠模糊掉 cache 的 inaccuracy 時,就可以中止 ray。具體公式是這樣:
\[a(x_1...x_n) = \left({\sum_{i=2}^{n}{\sqrt{ \dfrac{||x_{i-1} - x_i||^2}{p(w_i|x_{i-1}, w) | cos\theta_i} }}}\right)^2 > C × \dfrac{ {||x_0-x_1||}^2}{4 \pi cos \theta_1}\]$p$:BSDF sampling PDF
$\theta_i$:$w_i$ 與 Surface normal 的夾角
$C$:常數,0.01 為最佳
Training
不過因為多數的 Ray 只會打個兩三下就中止,因此這邊需要將 2~3% 的 ray 做延長來做為 AI 模型的訓練資料。這些 ray 所經過的所有 hit point 都會被作為訓練資料,丟入 Nerual Radiance Cache 內。
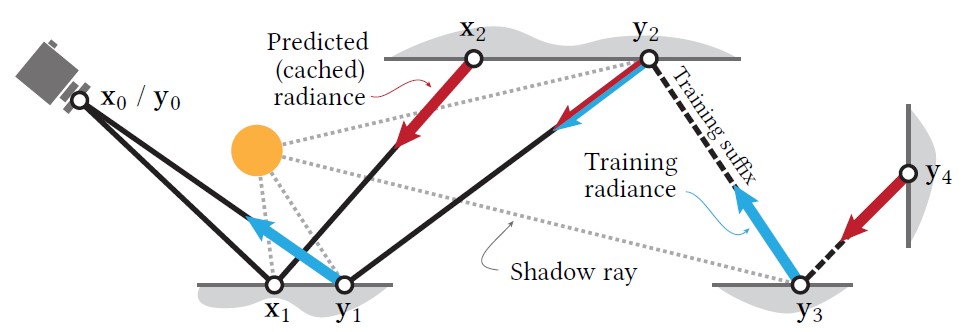
而具體的訓練資料內容可以參考下圖,有趣的地方在於這些參數會經過一個叫做 Position Encoding 的技巧編碼,簡單來說就是透過傅立葉去分析這些資訊的頻率,將原始資料從三維擴展到 36 維度,來加速神經網路的收斂速度。

這技巧在 NeRF 這篇論文中,有比對使用了 Position Encoding 後與沒有使用的結果。

有興趣的話可以參考以下幾篇論文:
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
- On the Spectral Bias of Neural Networks
- Random Features for Large-Scale Kernel Machines
高學習率
可是,要在 Render 過程的每一幀時間內,訓練並且預測 AI 模型,想也知道很困難。為了加速網路收斂,作者使用了高學習率搭配多個 gradient descent 去加速收斂。不過也導致了另一個問題 - Flickering。

解決方法也挺簡單,將 Trainging weight 與先前的 weight 取平均,避免震盪。那當然,這個取過平均的 weight 並不會拿回去做 training。
而取平均的方式則為 Exponential Moving Average,簡單來說就是離現在 frame 最接近的 weight 有著最高加權。
\(t: t^{th} \text{ frame}, \alpha = [0, 1]\) \(\alpha = 0.99 \text{ 時有最佳結果}\)
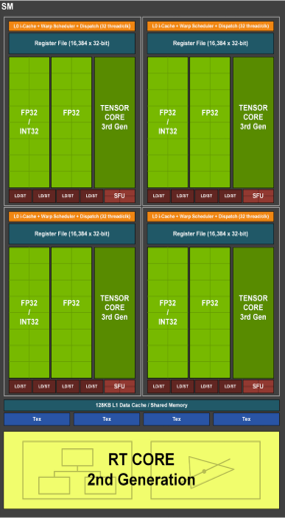
硬體最佳化
身為 NVIDIA 的論文,當然是要來推銷一下 NVIDIA 的顯示卡 (X
為了讓神經網路能夠在有限的時間內完成訓練與辨識,除了前面提到的一些技巧,作者更特別自己用 CUDA 寫了一個神經網路。並針對 RTX 3090 這張顯示卡特別優化網路架構,將神經網路的大小剛好設定成能夠塞進去 Tensor Core。而這 Tensor Core 是 NVIDIA 在 RTX 系列顯示卡所加入的一個硬體加速器,可以將 8x8 的矩陣相乘,加速神經網路的運算速度。
NVIDIA GeForce RTX 3090
| CUDA Core | 運算單元 |
|---|---|
| Tensor Core | 神經單元 |
| RT Core | 光線追蹤單元 |
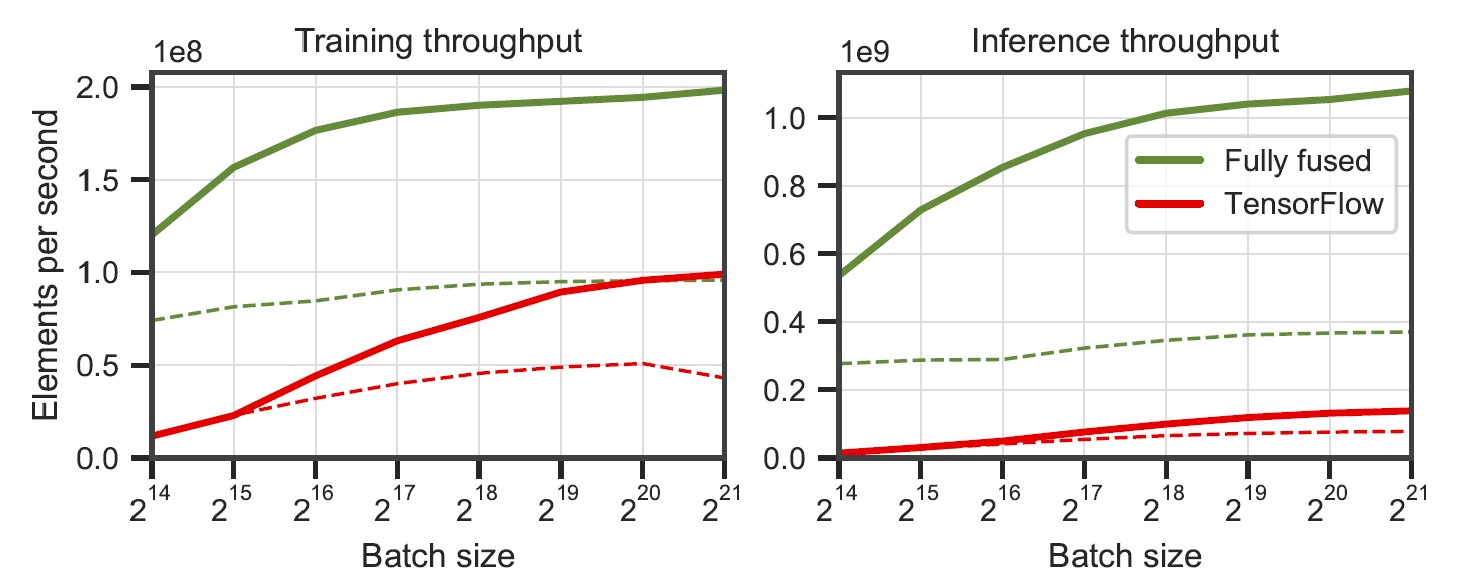
透過這張圖可以看到,相比 TensorFlow,自己寫的神經網路可以在 RTX3090 上達到更快的效果。有興趣的話可以仔細看一下論文的方法。
總結
那看到成果的部分,首先是究竟要 Train 幾個 frame,模型才能生出足夠好的效果呢?作者這邊試驗大概 8 個 frame 後,Radiance cache 的成果就已經很不錯了。
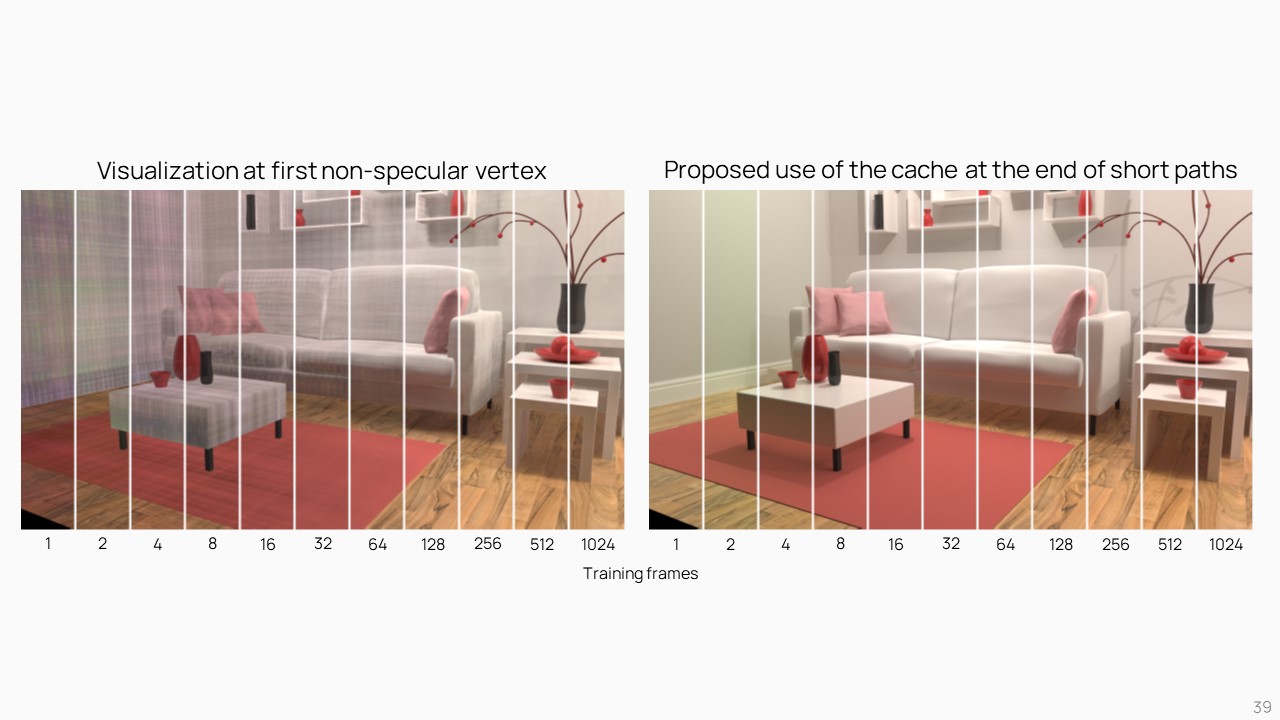
Cache Lag
不過畢竟是在渲染的同時訓練,因此當場景變動時,可能會出現 Cache lag 的情形。

流程整理
簡單整理一下流程
- 從眼睛往螢幕像素打出射線
A. 第一個碰撞點用 ReSTIR Sample
B. 第二個碰撞點之後用 BSDF Sample - 在碰撞幾次後,終止射線,並將終點座標與方向輸入 Radiance Cache
A. 拿出該點的 Radiance 後,依據材質算出 specular 與 diffuse color 並回傳 - 延長 2~3% 的射線,將射線中的所有碰撞座標含 Radiance 拿去訓練 Radiance cache
- 將 Radiance cache 的 Weight 取平均,作為之後預測用(不會拿回去訓練)
- Denoise
成果圖
作者在他的個人網站有放成果圖對比,連結在這。
對比其他方法,在有限時間內的渲染,NRC 的結果是最好的。


這大概就是 Neural Radiance Cache 這篇論文的簡單介紹,論文寫的挺清楚的,也有原始碼可以查找。論文主要核心在於渲染的同時進行訓練與預測,同時藉由 CUDA 手刻網路來提高效率。
那這篇是阿湯第一次寫論文的簡介,如果錯誤歡迎留言指正我,也感謝看到這裡的客官們。
留言