
「專案筆記」Manga Inpainting and Restoration based on Latent Diffusion Model and Symmetric VAE
漫畫是種獨特的藝術創作,內容由純黑白的網點 (Screentone) 與結構線 (Structural Line) 構成,營造出不同於彩色和灰階的獨特視覺效果及意義。而漫畫,多數源自於日本,因此在其他國家,例如台灣,想要享受漫畫的樂趣,就必須透過翻譯。然而,現有的漫畫翻譯僅針對文字部分,對於漫畫中的狀聲詞皆不會翻譯。而對於互動式的漫畫,現有的系統也僅限於將對話框 (Speech Bubble) 依據閱讀順序放大,互動性有限。我認為這是因為目前不存在一個足夠強的 inpainting 系統,能夠將對話框底下的內容以合理的像素填上,假如存在一個足夠好的 inpainting 系統,將可以達成狀聲詞的翻譯和使對話框能夠依據閱讀順序逐一出現。除此之外,對於老舊的漫畫翻譯,還需要大量人力去將掃描下來紙張中的黃化和老化瑕疵移除,因此,本研究提出了 Manga Diffusion Inpainting Model (MDIM),能夠對漫畫進行 inpainting 和 restoration。
問題
空白處畫頭
直接將 LDM 用在漫畫 Inpainting 上有著很多的問題,其中最明顯的莫過於填補頭,如下圖,可看到 LDM 會想盡辦法將人物的頭補到空白區域。你或許會想,這應該是資料有 bias 的關係吧?畢竟漫畫的圖片大多都有人物,但是,實際透過較少人物的漫畫資料集訓練後,雖然不再繼續畫頭,但是空白區域仍然出現了一堆奇怪的圖騰呀!


細節網點 (Screentone) 失真
LDM 將 Diffusion 從 Pixel Space 轉移到 Latent Space 中,這樣的方法大幅降低了運算複雜度和記憶體的用量,然而,這樣的架構也導致了細節失真的問題。VAE 的壓縮是一種有損的壓縮,因此,當我們將圖片轉換到 Latent Space 後,再轉回 Pixel Space 時,細節會有所失真。這對於 Inpainting 來說,是一個很大的問題,尤其這個失真在網點的形狀上表現得尤為明顯,如下圖。

模型
本研究提出的 Manga Diffusion Inpainting Model (MDIM) 模型延伸自 Latent Diffusion Model (LDM),即大家所熟知的 Stable Diffusion,但如前一章節所提到的,LDM 無法應付漫畫,因此本研究針對這些問題,對 LDM 做了訓練上和架構上的修改之後,提出了 MDIM。以下說明 MDIM 確切的修改。
訓練上的修改
Lin 等人發現了 LDM 的 Noise Scheduler 是有缺陷的,造成 LDM 無法生成太亮或是太暗的圖片,本研究引入了修正後的 Noise Scheduler,確保訓練和推理時,Signal-to-noise Ratio (SNR) 為 0,使其能夠生成純黑或是純白的圖片。

導入了 Noise Scheduler 後,其實已經解決了很大部分的問題,但是,LDM 生成人頭的問題尚未解決,因此,我提出和導入了多個方式來改善。
- Inpainting Mask
首先,我以75%的機率,將 Inpainting 遮罩設為整張圖,這樣可以提升 LDM 繪圖的能力。 - 乾淨的漫畫
接著,我將漫畫的對話框、文字和狀聲詞從漫畫中移除,確保這些部分不會被 Inpainting,這樣可以讓 LDM 專注在漫畫的網點和結構線上。 - 低 Learning Rate 和 低 Batch Size
LDM 是一種很容易 overfitting 的模型,太高的學習率容易訓練失敗。但是,除此之外,我發現使用 DreamBooth 方法訓練 LDM 時,如果資料太過單一風格,例如黑白的漫畫,那麼 Batch Size 太高也會導致訓練失敗。因此,我將 Learning Rate 設為1e-6,Batch Size 設為4。 - 提詞 (Prompt)
提詞在 Inpainting 模型訓練中其實沒有這麼重要,影響並不到太大,本研究透過 DeepDanBooru 辨識出的 Tag,隨機排列為提詞,搭配漫畫風格的提示詞,如"manga, manga style, comic, monochrome, " + TAGS。或是,透過 Gemini API,也可以生成品質不錯的圖片提詞。
結合以上的方法,我成功訓練出了 MDIM 模型,能夠對漫畫這類黑白分明的影像達成 SOTA 的漫畫 Inpainting。
高解析度 Inference
我觀察到,LDM 於高解析度 Inference 時,其生成的內容往往比低解析度差,因此,本研究提出了Semantic Guidance Inpainting Method (SGIM),以 Diffusion Model 的特性,透過兩階段方法來提升 Inpainting 內容的合理性,第一階段 Semantic Guidance Inpainting (SGI),會於低解析度進行 Inpainting,建構關鍵的結構線條;第二階段 Full Resolution Inpainting (FRI),會以先前的低解析度結構為基礎去修復細節。避免因為高解析度特徵與訓練時不同,造成的特徵誤判,從而提高模型在高解析度下的表現。
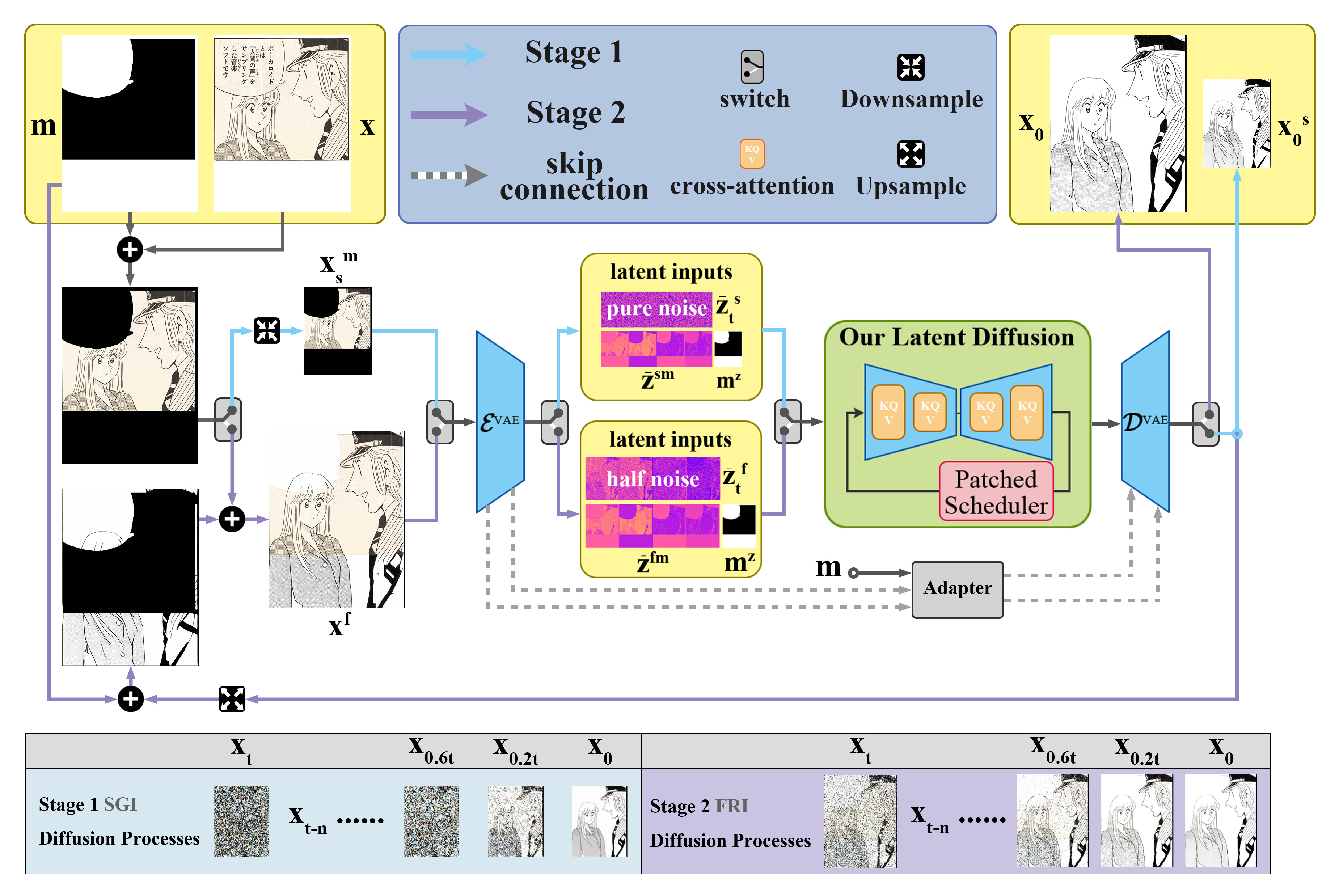
具體而言,在低解析度 SGI 階段,我會將影像最長邊逐步縮小到 1024 以下,此時,進行一次一般的 Inpainting,接著放大圖片,以 0.5 的 Strength,再次進行 Inpainting,此為 FRI 階段。0.5 的 Strength 意味著 Diffusion 會從一半的時間步開始進行 Denoise,輸入的圖片會在 Noise Scheduler 加上一半強度的 Noise 後,餵給 Diffusion Model 進行 Denoise,這樣 Diffusion 就能夠依據圖片內原本的內容,稍微的做修改,達到保留主要結構,但提升解析度的目的,以下這張圖展示導入 SGIM 和未導入的差異。

Symmetric VAE
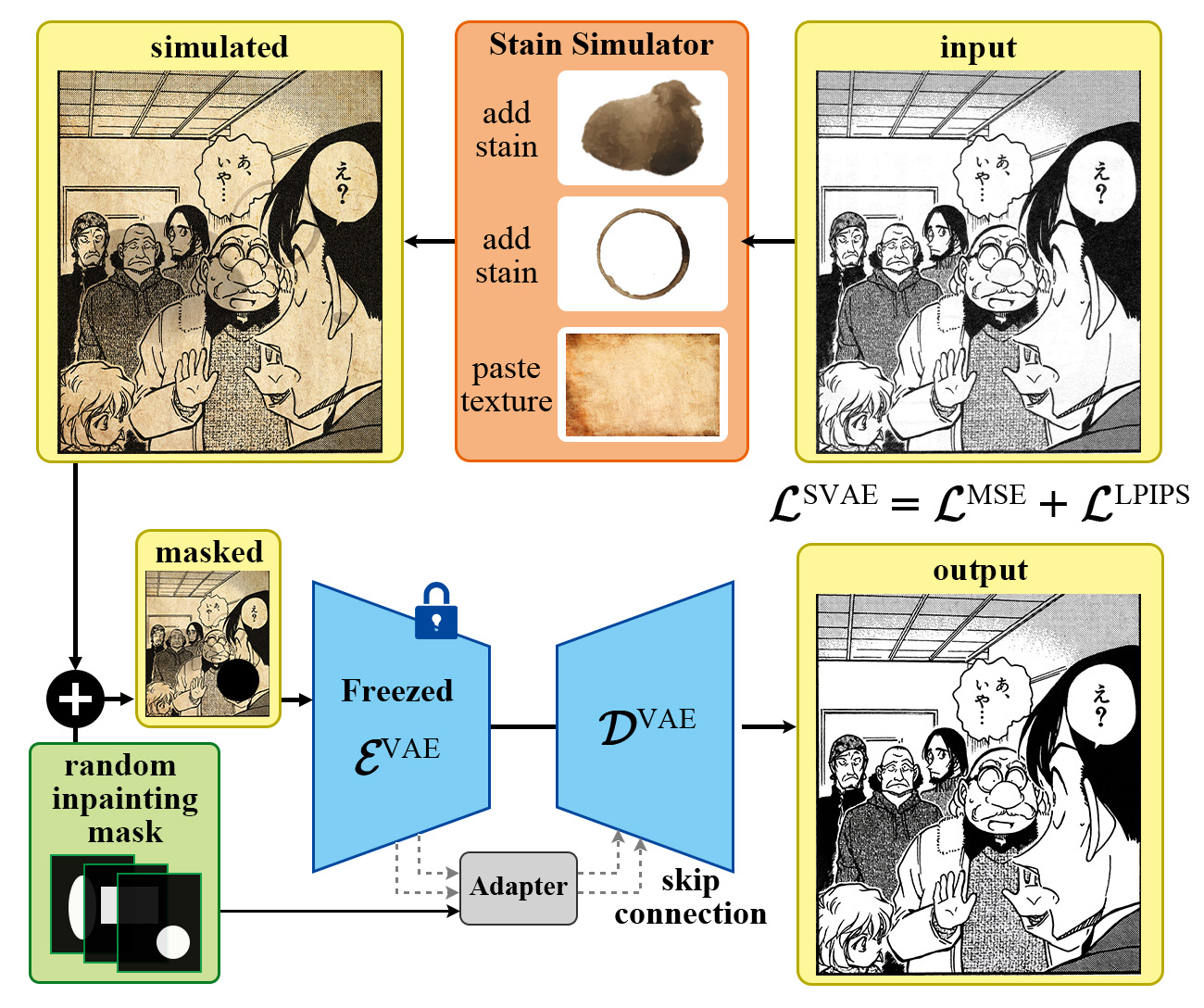
前面提到了 VAE 導致的失真問題,因此我提出了一個新的 VAE 架構,Symmetric VAE。之所以叫做 Symmetric VAE,是因為先前研究中,有個模型叫做 Asymmetric VAE,它藉由額外的 CNN Encoder 和增大的 Decoder,來改善失真問題。但是,這樣的做法在 512×512 的圖片中,需要大約 400MB 額外的記憶體消耗,而且還需要大量訓練才能使用。我的想法更為簡單,首先,失真可以視為一種資訊的丟棄,Encoder 會學習一張影像中重要的結構,將這些重要特徵萃取出來,成為 Latent Vector。而 Decoder 則要透過這些 Latent Vector 來重建影像。理想上,Encoder 會學習到所有重要的結構特徵,丟棄人眼辨別不出的次要特徵,使 Decoder 仍能夠還原出視覺上與原本影像無差異的圖片。而這樣的原理也被應用在老舊文件的 Restoration 上。正好,老舊漫畫的 Restoration 也是常見的需求,因此,我針對原始 VAE 會失真的問題,提出了 Symmetric VAE 來改善。藉由 Restoration 的導入和 VAE 架構的改進,來減少 VAE 造成的失真,同時額外達成 Restoration 的目標。
架構
Symmetric VAE 的架構如下圖,首先,影像會經過 Encoder,產生出 Latent Vector,但與一般 VAE 不同的是,我會將 Encoder 各層的特徵保留下來,接著,各層的特徵會經過 Adapter,將維度轉換到和 Decoder 各層相同。這樣做的原因在於 Encoder 和 Decoder 實際上並不是完全對稱的,因此,需要透過一個簡單的 CNN Adapter 來轉換維度。最後,Decoder 吃進轉換後的特徵和 Latent Vector,重建影像。
訓練
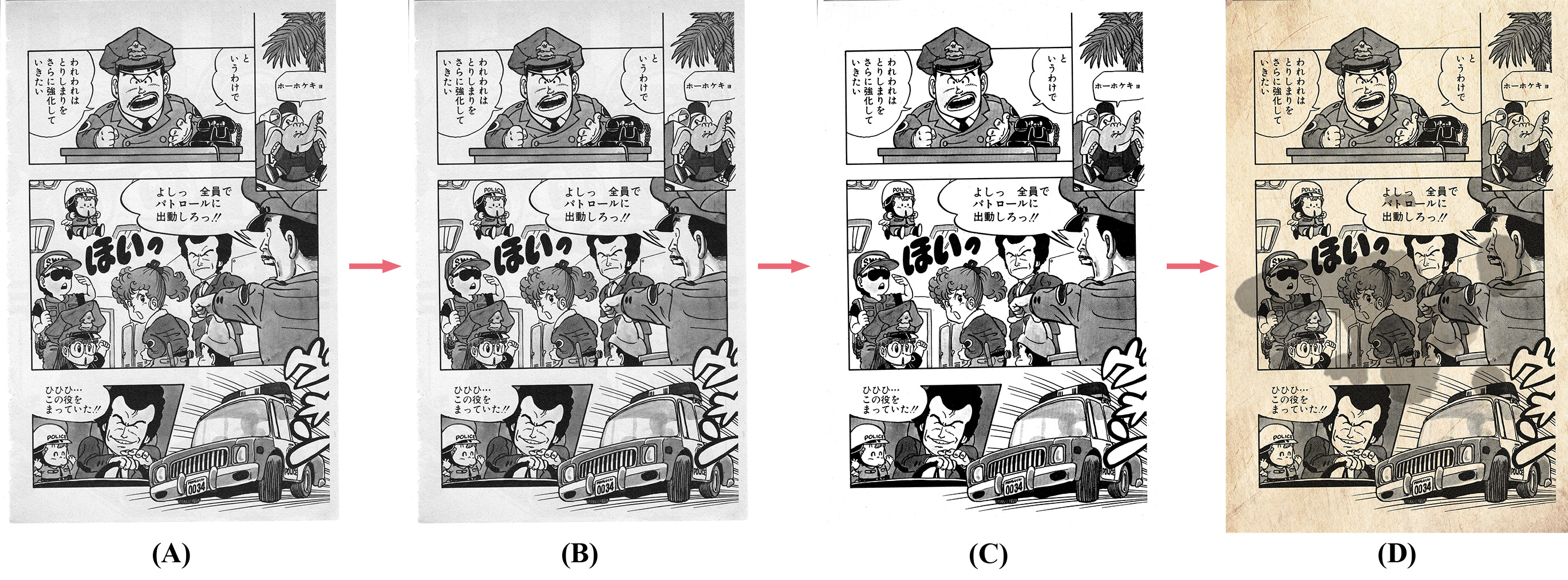
由於 Restoration 的需要,除了使用大量漫畫影像進行訓練,我還透過模擬的方式,生成大量的老舊漫畫影像。將這些髒汙的老舊漫畫輸入進模型後,透過 Loss 的調整,使模型學習輸出一張乾淨黑白的影像,以達成漫畫 Restoration 的目的。其中,以模擬的方式來訓練漫畫 Restoration,原因在於這樣的方法能夠大幅增加髒汙、黃化和老化的樣式,只要蒐集多種的髒汙材質,便可以在不同的漫畫和不同風格的網點上展現出不同的髒汙組合。此外,為了使漫畫還原的 Ground Truth 目標,不會被訓練資料的輕微髒汙和老化影響,我也以自動對比度、色彩映射和彩色轉灰階,將訓練資料的輕微老化移除。具體來說,是將輸入影像轉為灰階,計算 Histogram 後,將最亮和最暗處重新映射到 0 和 255,最後再透過線性映射,將像素值 90 到 190 內的像素,映射回 0 到 255,具體數值可針對不同資料集做調整,如下圖。
Inpainting 比較
為了驗證我提出的 Manga Diffusion Inpainting Model (MDIM) 優於其他的 Inpainting 方法,在此章節,將透過不同的評估指標和 User Study 來驗證。
| 方法 | Ours | Xie et al. | Stable Diffusion | LaMa |
|---|---|---|---|---|
| CMMD | 0.033 | 0.164 | 0.127 | 0.143 |
| FID | 53.7255 | 79.1470 | 65.1679 | 65.5315 |
| LPIPS | 0.09495 | 0.11769 | 0.10625 | 0.09165 |
Metrics
目前多數研究在評估 Inpainting 效果時,皆會使用 LPIPS 和 FID 等指標。然而,多偏研究表明,對於生成式模型的評估,這些傳統的評估指標其實是有缺陷的,應該要以 User Study 來評估比較好,所以,這邊的分數就僅提供參考。
其中,測試資料部分,本研究從26本漫畫中,挑選出不包含對話框、狀聲詞和文字的畫格,共 183 個做為 Inpainting 的測試資料。本論文假設,給定一張影像,給予一個隨機的遮罩後,產出的 Inpainting 結果應該要與原圖相似,理想上與原圖相同。因此,透過計算 Inpainting 後的影像和原使圖片的相似度,即可作為 Inpainting 的評估指標。
1. CMMD
CLIP embeddings and the Maximum Mean Discrepancy (CMMD) 是 Google 新提出的一種評估方法,目的在取代已經老舊的 FID 評估指標。CMMD 採用了新的 MMD 算法和使用 CLIP Vision Transformer 來計算兩張圖片之間的相似度,這樣的方法能夠更好的評估生成式模型的效果。CMMD 的數值越低,代表結果與 Ground Truth 越相似。從結果看來,我的方法在漫畫上碾壓了其他的 Inpainting 方法。
2. LPIPS
Learned Perceptual Image Patch Similarity (LPIPS) 是一種透過神經網路,計算影像相似度的評估指標。其計算方式是計算 AlexNet 或是 VGG16 的特徵層相似度,因此,LPIPS 指標反應的相似度僅是結構相似度,而非內容何不合理。而這樣的相似度計算也造成了這些指標很難判定 Inpainting 方法的好壞,畢竟,Inpainting 追求的是在空白處補上合理的內容,而非完全相同。從結果看來,本研究的方法在 LPIPS 指標上,略遜於 LaMa,但是仍然優於 Stable Diffusion 和 Xie et al. 的方法。
3. FID
Fréchet inception distance (FID) 是一種常用的生成式模型評估指標,用來評估生成式模型生成影像集與真實影像集之間的分佈差異。其計算方式是透過計算 Inception 模型中,多維度特徵向量的 Frechet Distance,來評估真實影像與生成影像之間的相似度。該距離越小,代表兩組圖片的相似度越高。此指標於近期研究中,如:Emu、SDXL 和 Pick-a-Pic,被指出不適合用來評估生成式模型。但是,考慮到 FID 的廣泛性,這邊還是提供了 FID 的評估結果。從結果看來,本研究的方法在 FID 指標上,碾壓了其他的 Inpainting 方法,但是需要注意到,FID 通常需要數千張的影像評估,才能有比較精確的分數,本研究的測試資料並沒有那麼多,因此結果僅供參考。
User Study
為了驗證本研究提出的 Manga Diffusion Inpainting Model (MDIM),我使用了 User Study 來驗證本研究的方法相比 Xie et al. 的漫畫 Inpainting 模型、Stable Diffusion Inpainting v1.5 和 LaMa 在漫畫上的 Inpainting 效果。
問卷設計
本論文以一對一對比的方式為基礎,確保獲得準確的排名,減少受測者的認知負荷,增加判斷的可靠性。本論文以本研究觀察到常見的五種類別漫畫場景,包含人物、空白、結構、物件與漫畫特效做分類,從訓練資料以外的11本漫畫中在每個類別隨機挑選 5 張畫格進行 Inpainting 後,交由使用者評估。當中針對每種方法都會進行兩兩的比較,使用者會被詢問「以下兩張圖片之中,你認為何者的內容較為合理?」,並且,在左右兩張影像中,選擇一張視覺感受較為合理自然的影像。所有題目皆以隨機順序排列,確保實驗結果不會受到作答順序而有著特定的偏好,所有問題皆於同一個頁面顯示。在回答問卷之前,使用者會被指示需要參考以下因素:
- 修復區域的自然度:修復區域是否與周圍環境融合良好,是否存在不自然的邊緣或色彩差異。
- 細節再現程度:修復區域的細節再現程度,如紋理、陰影等。
- 體畫面意義的保留:修復區域是否影響整體畫面的意義。
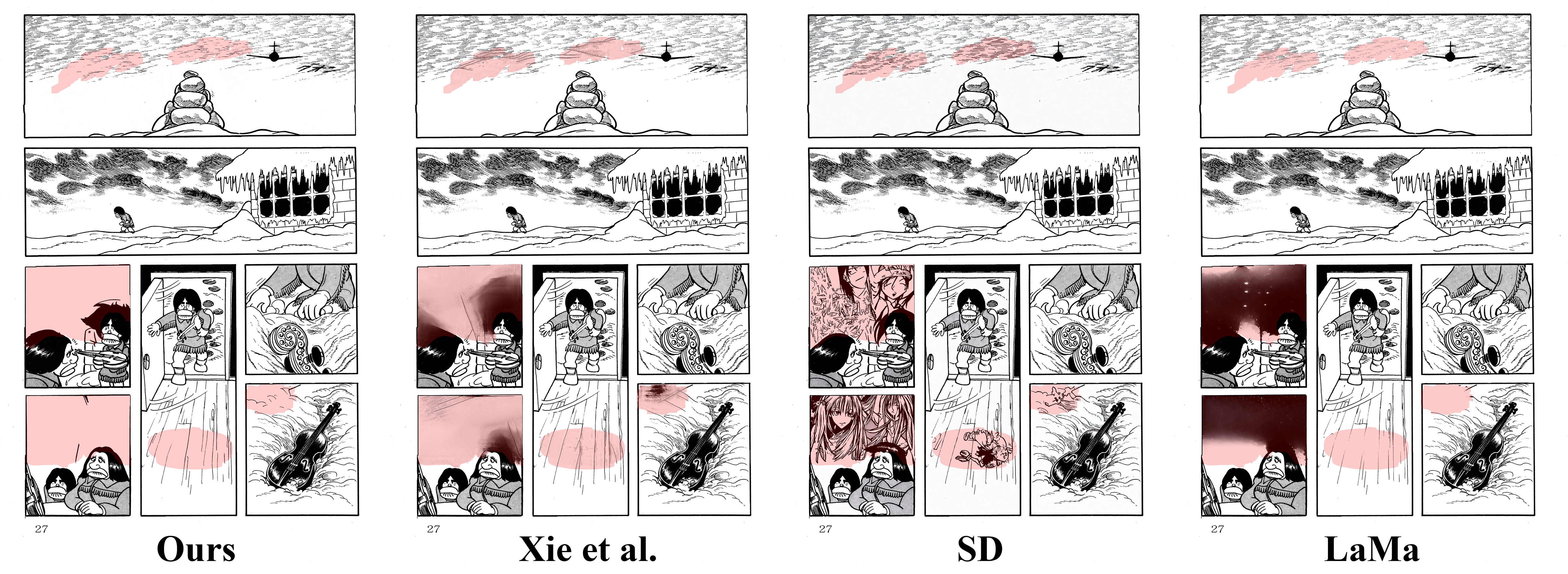
以本次問卷比較本研究的方法、LaMa、Stable Diffusion Inpainting v1.5 (SD) 與謝等人提出的漫畫 Inpainting 模型 (Xie et al.)。每張圖都會有 $\binom{4}{2}=6$ 種組合的影像配對供使用者挑選。在每個問題中,分別會把兩種方法的結果放在最左與最右邊,中間顯示輸入影像,同時使用半透明紅色標示出 Inpainting 的遮罩位置,方便使用者判斷,如下圖。

結果分析
User Study 的結果如下表所示,可以看到本研究的方法除了在漫畫特效上略遜於 LaMa 以外,於各項分類都是大幅碾壓其他的 Inpainting 方法,可見本研究的方法優於其他者。
| 類別 | 圖片組 | u | ζ(avg) | χ² | 1st | 2nd | 3rd | 4th |
|---|---|---|---|---|---|---|---|---|
| 結構 | 1 | 0.314 | 0.904 | 53.077 | Ours | LaMa | SD | Xie et al. |
| 2 | 0.722 | 1 | 114.3 | Ours | LaMa | Xie et al. | SD | |
| 3 | 0.521 | 0.904 | 84.15 | Ours | LaMa | Xie et al. | SD | |
| 4 | 0.473 | 0.865 | 76.92 | Ours | LaMa | Xie et al. | SD | |
| 5 | 0.751 | 0.981 | 118.6 | Ours | LaMa | Xie et al. | SD | |
| 物件 | 1 | 0.667 | 0.981 | 106 | Ours | SD | LaMa | Xie et al. |
| 2 | 0.575 | 0.904 | 92.31 | Ours | LaMa | Xie et al. | SD | |
| 3 | 0.667 | 0.962 | 106 | Ours | SD | LaMa | Xie et al. | |
| 4 | 0.544 | 0.981 | 87.54 | Ours | LaMa | Xie et al. | SD | |
| 5 | 0.442 | 0.981 | 72.308 | Ours | LaMa | Xie et al. | SD | |
| 人物 | 1 | 0.747 | 0.981 | 118 | Ours | LaMa | Xie et al. | SD |
| 2 | 0.872 | 1 | 136.8 | Ours | LaMa | Xie et al. | SD | |
| 3 | 0.49 | 0.885 | 79.54 | LaMa | Xie et al. | Ours | SD | |
| 4 | 0.424 | 0.904 | 69.54 | Ours | Xie et al. | LaMa | SD | |
| 5 | 0.679 | 0.962 | 107.8 | Ours | LaMa | Xie et al. | SD | |
| 空白 | 1 | 0.714 | 0.942 | 113.1 | Ours | LaMa | Xie et al. | SD |
| 2 | 0.777 | 0.923 | 122.6 | Ours | LaMa | Xie et al. | SD | |
| 3 | 0.792 | 0.962 | 124.8 | Ours | LaMa | Xie et al. | SD | |
| 4 | 0.555 | 1 | 89.23 | Ours | LaMa | Xie et al. | SD | |
| 5 | 0.592 | 0.981 | 94.77 | LaMa | Xie et al. | Ours | SD | |
| 漫畫特效 | 1 | 0.533 | 0.942 | 86 | SD | Ours | Xie et al. | LaMa |
| 2 | 0.41 | 0.904 | 67.54 | Ours | LaMa | Xie et al. | SD | |
| 3 | 0.528 | 0.962 | 85.23 | LaMa | Ours | Xie et al. | SD | |
| 4 | 0.546 | 0.962 | 87.85 | LaMa | Xie et al. | Ours | SD | |
| 5 | 0.617 | 1 | 98.62 | LaMa | Ours | Xie et al. | SD |
結果示例
最後,為了視覺話本研究於漫畫 Inpainting 的成果,本論文將展示本研究將 Inpainting 應用於整頁漫畫上的效果。為了減少記憶體的使用和避免畫格外的內容影響漫畫 Inpainting,本研究將畫格從漫畫的頁面上切割下來獨立計算後,再貼回頁面上,流程如下圖。
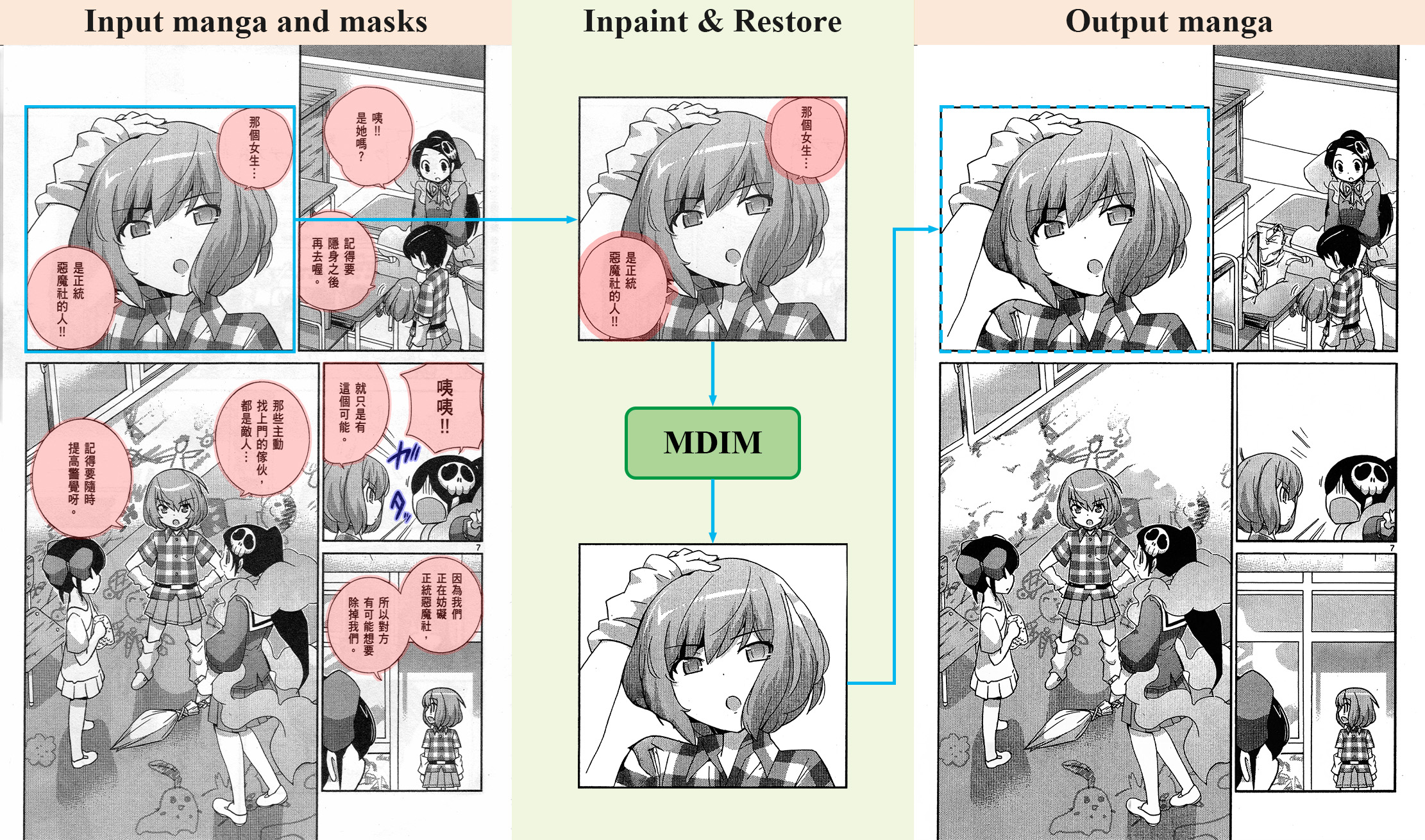
成果如下,為了避免圖片太大,影響網站速度,以下圖片有進行 50% 的縮放和 JPEG 壓縮。



Restoration 比較
為了驗證本研究所提出的 SVAE 於漫畫 Restoration 上的表現,本研究以 FID、LPIPS 與 PSNR 評估指標,對比 Symmetric VAE,以下簡稱為 SVAE,和針對文件設計的 Document Enhancement Generative Adversarial Networks,以下簡稱為DE-GAN,於漫畫 Restoration 上的表現。此次對比使用的是來自論文作者的程式碼,使用預設參數和模型,以文件二值化模式進行處理。由於,目前並沒有針對老舊漫畫 Restoration 的研究,因此,本論文僅能使用針對老舊文件的方法來進行比較。此外,為了量化本論文所使用的測試資料黃化程度,本論文將使用國際照明協會 (CIE) 提出的 CIE2000標準 Delta E,定義為 Δ${E^{}_{00}}$ 來計算色差。透過將各漫畫與 Ground Truth 之間的 Δ${E^{}{00}}$,以及各漫畫與自身灰階圖之間的 Δ${E^{*}{00}}$ 紀錄於表。可以得到同時考量影像亮度與顏色,以及指考量顏色差異的色差值,此數值越小,代表色差越小。
| 評估指標 | 漫畫 | 亮度和色差 Δ${E^{*}_{00}}$ | 色差 Δ${E^{*}_{00}}$ | DE-GAN | Ours |
|---|---|---|---|---|---|
| FID | 天使日誌 | 11.94 | 1.907 | 101.0 | 25.59 |
| 名偵探柯南 | 19.13 | 0.813 | 222.7 | 13.79 | |
| 古靈精怪 | 15.46 | 2.794 | 214.2 | 35.37 | |
| 烏龍派出所 | 11.29 | 1.303 | 149.4 | 16.64 | |
| 美食偵探王 | 16.75 | 1.020 | 153.0 | 14.10 | |
| 小鮒魚的學校 | 10.01 | 0.169 | 163.3 | 17.23 | |
| 天才柳澤教授 | 10.91 | 1.067 | 109.5 | 11.40 | |
| 天體戰士桑雷德 | 14.50 | 1.144 | 261.4 | 31.15 | |
| 向陽之樹 | 21.96 | 0.871 | 109.1 | 6.239 | |
| 全部 | - | - | 118.0 | 14.51 | |
| PSNR | 天使日誌 | 11.94 | 1.907 | 12.27 | 23.04 |
| 名偵探柯南 | 19.13 | 0.813 | 9.707 | 26.40 | |
| 古靈精怪 | 15.46 | 2.794 | 9.633 | 23.04 | |
| 烏龍派出所 | 11.29 | 1.303 | 9.915 | 24.12 | |
| 美食偵探王 | 16.75 | 1.020 | 9.671 | 24.28 | |
| 小鮒魚的學校 | 10.01 | 0.169 | 9.734 | 26.91 | |
| 天才柳澤教授 | 10.91 | 1.067 | 9.974 | 24.50 | |
| 天體戰士桑雷德 | 14.50 | 1.144 | 9.932 | 24.50 | |
| 向陽之樹 | 21.96 | 0.871 | 9.903 | 29.60 | |
| 全部 | - | - | 9.903 | 25.16 | |
| LPIPS | 天使日誌 | 11.94 | 1.907 | 0.1757 | 0.1741 |
| 名偵探柯南 | 19.13 | 0.813 | 0.2615 | 0.0795 | |
| 古靈精怪 | 15.46 | 2.794 | 0.2567 | 0.2304 | |
| 烏龍派出所 | 11.29 | 1.303 | 0.2491 | 0.0733 | |
| 美食偵探王 | 16.75 | 1.020 | 0.2572 | 0.0772 | |
| 小鮒魚的學校 | 10.01 | 0.169 | 0.2604 | 0.0360 | |
| 天才柳澤教授 | 10.91 | 1.067 | 0.2565 | 0.0819 | |
| 天體戰士桑雷德 | 14.50 | 1.144 | 0.2557 | 0.1055 | |
| 向陽之樹 | 21.96 | 0.871 | 0.2587 | 0.0653 | |
| 全部 | - | - | 0.2587 | 0.1026 |
Metrics
為了透過評估指標來客觀評量本研究的方法於漫畫 Restoration 上的效果,我從經長久存放的老舊漫畫中,蒐集了 9 部 10 卷有著較為嚴重,且不同程度老化的漫畫,每卷隨機選擇 10 頁,共準備了 90 筆的測試資料,並以 600 DPI 掃描下來的紙本頁面做為模型輸入。而 Ground Truth 則使用專家經由 Adobe Photoshop 影像處理復原的輸入影像,影像處理包含轉換為灰階、表面模糊移除紙張瑕疵和使用修復筆刷去除雜點,最後透過顏色映射,將多數的像素映射到全黑和全白,以評估指標評估 Ground Truth 與模型輸出的差異。
1. FID
Fréchet inception distance (FID) 是一種常用的生成式模型評估指標,用來評估生成式模型生成影像集與真實影像集之間的分佈差異。其計算方式是透過計算 Inception 模型中,多維度特徵向量的 Frechet Distance,來評估真實影像與生成影像之間的相似度。該距離越小,代表兩組圖片的相似度越高。從結果看來,本研究的方法在 FID 指標上,碾壓了 DE-GAN,但是需要注意到,FID 通常需要數千張的影像評估,才能有比較精確的分數,本研究的測試資料並沒有那麼多,因此結果僅供參考。
2. PSNR
Peak Signal-to-Noise Ratio (PSNR) 是一種用來評估影像重建或是壓縮品質的客觀指標,其表示了訊號最大的可能功率與影響其表示精度之間的比值。PSNR 能夠反應訊號有用之訊息強度與雜訊之間的比例,其數值越高,代表雜訊影響越低,表現越好。從結果看來,本研究的 SVAE 毫無懸念的贏過了 DE-GAN。
3. LPIPS
Learned Perceptual Image Patch Similarity (LPIPS) 是一種透過神經網路,計算影像相似度的評估指標。其計算方式是計算 AlexNet 或是 VGG16 的特徵層相似度,更能精確反應符合人類視覺的相似度指標,其分數越低,代表影像的相似度越高。從結果看來,本研究的方法強於 DE-GAN。
結果示例
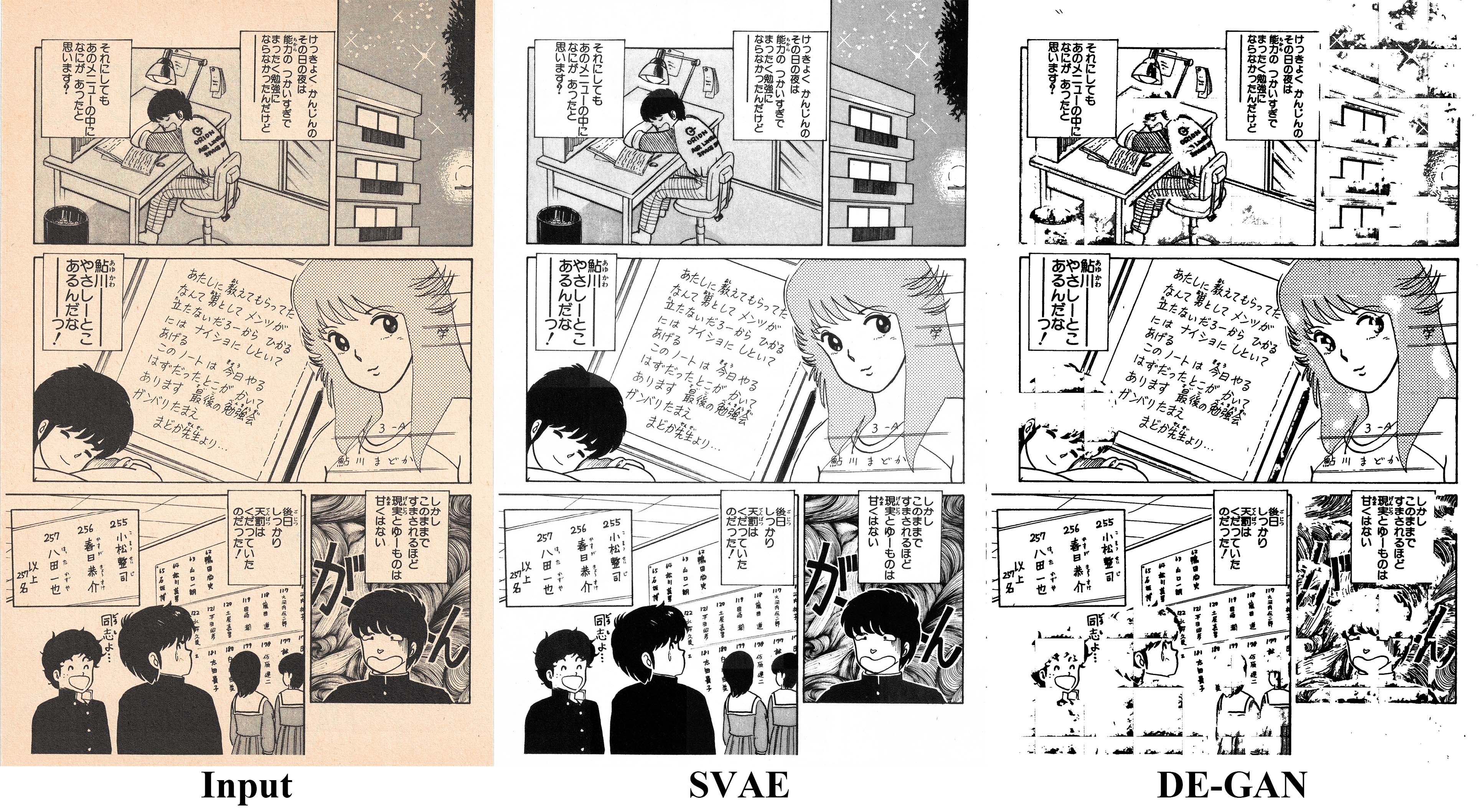
最後,為了視覺話本研究於漫畫 Restoration 的成果,本論文將展示本研究將 Restoration 應用於測試資料漫畫上的效果。
成果如下,為了避免圖片太大,影響網站速度,以下圖片有進行 50% 的縮放和 JPEG 壓縮。


留言