
Image Similarity Search & Image Semantic Search
Image Similarity Search 顧名思義,就是輸入一張影像後,尋找與其類似的影像。而 Image Semantic Search 則是透過自然語言,尋找與文字描述相符的圖片。以前這類搜尋都是透過一些演算法比對影像特徵,或是訓練一個分類網路,依不同類別分類後給用戶尋找。但隨著近期 CLIP 網路的出現,這類搜尋方式不再需要侷限在這些演算法與各種分類網路了。在這個專案中,將透過 CLIP 這個 Vision Transformer (ViT),將影像編碼成 Image Embedding 後,透過向量資料庫 Milvus,尋找 Embedding 相似的影像,並顯示出來。同時,也可以透過 CLIP 的 Text Encoder,以文字查詢類似的圖片。搭配 Gradio 作為操作介面。
CLIP
CLIP (Contrastive Language-Image Pretraining),是一款由 OpenAI 推出的 Vision Transformer (ViT)。CLIP 透過將大量的 文字-影像 配對的資料集,透過對比式學習預訓練了一個 ViT 與 Text Encoder。
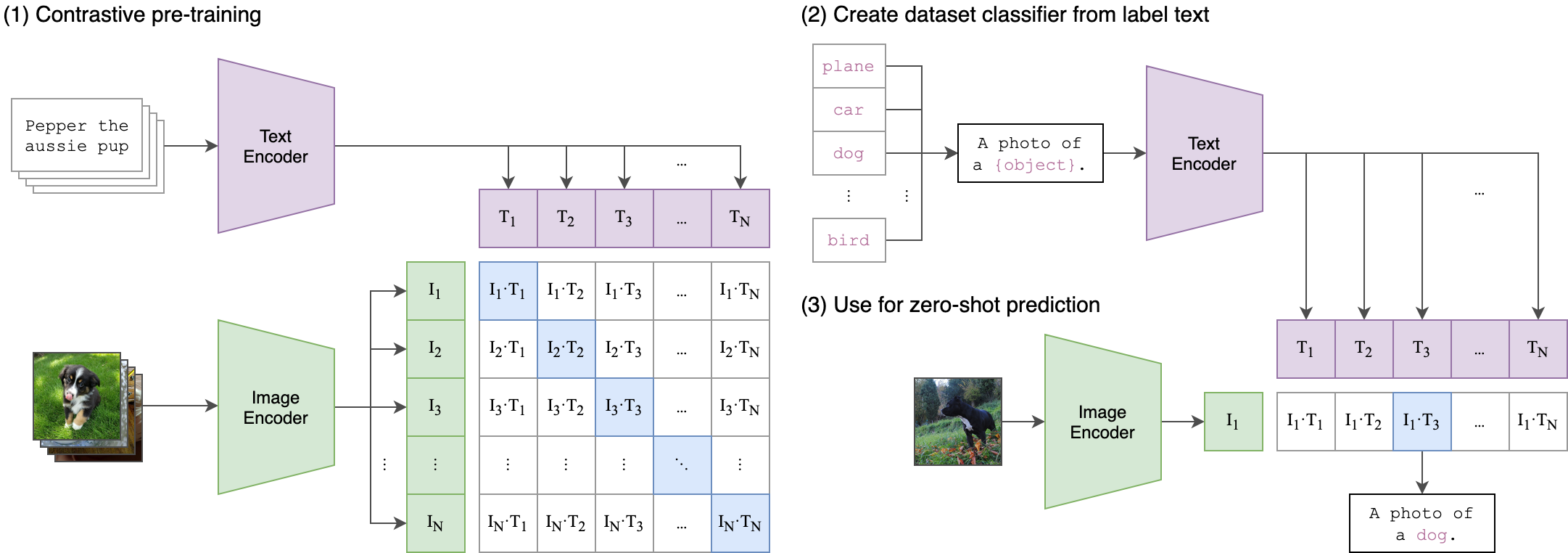
而由於訓練時,ViT 與 Text Encoder 是一同做對比訓練的,兩者產出的 embedding 會有著相關的特徵分佈,意味著可以透過文字來尋找影像的相似度,達成 zero-shot classification,或是本專案要做的 - Semantic Search。
原理挺簡單的,將影像透過 CLIP 的 Image Encoder,也就是 ViT Encode 後,獲取 embedding 的 CLS token。同時,也將文字透過 CLIP 的 Text Encoder 編碼後,獲得文字的 embedding。此時將這兩個 embedding 做 cosine similarity 後,即可獲得兩者之間的相似度。
Milvus Vector DB
近期的 transformer 類模型,在計算後會產生一個叫做 Embedding 的向量特徵。這個向量特徵可以作為一段文字、一張圖片、一個概念的表示。
由於所謂的 Embedding 是由一長串的浮點數組合而成,普通資料庫並沒有有效處理這些資訊的能力,因此向量資料庫出現了。向量資料庫可以用於儲存、暫存、搜尋向量,做到 semantic search、LLM 模型短期記憶、近似搜尋等。其中,最有名的莫過於 Pinecone 向量資料庫,但因為這個要錢,所以我選擇了開源,且可以自架的 Milvus Vector DB。
實作
首先 UI 的部分,選用了很容易上手的 Gradio 作為框架。左邊為參數設定與影像上傳區域,上傳影像後,可以按左下角的 Upload Image 將影像上傳到 Server 上。上傳後,會透過 hash 將影像內容編碼成一個獨特的 ID,作為影像的存取 ID,並儲存在 server 上。同時,將影像透過 transformers library 編碼成 embedding,儲存到 Milvus DB 內。
image = CLIPProcessor.(images=image, return_tensors="pt")
feature = CLIPModel.get_image_features(**image)[0]
db.insert(f"images/{uid}.png", feature)
搜尋的部分,則依據 input 的不同,如果是文字的話,就透過 text encoder 將文字轉為 embedding。反之,影像則透過 ViT encode。
text = AutoTokenizer.tokenizer(text=text, padding=True, return_tensors="pt")
feature = CLIPModel.get_text_features(**text)[0]
image = CLIPProcessor.(images=image, return_tensors="pt")
feature = CLIPModel.get_image_features(**image)[0]
然後,透過 Milvus DB 以 cosine similarity 尋找 embedding 相近的結果。
self.collection.load()
search_params = {"metric_type": "COSINE", "params": {"nprobe": 5}}
results = self.collection.search([embedding], "img_emb", earch_params, limit=5)
self.collection.release()
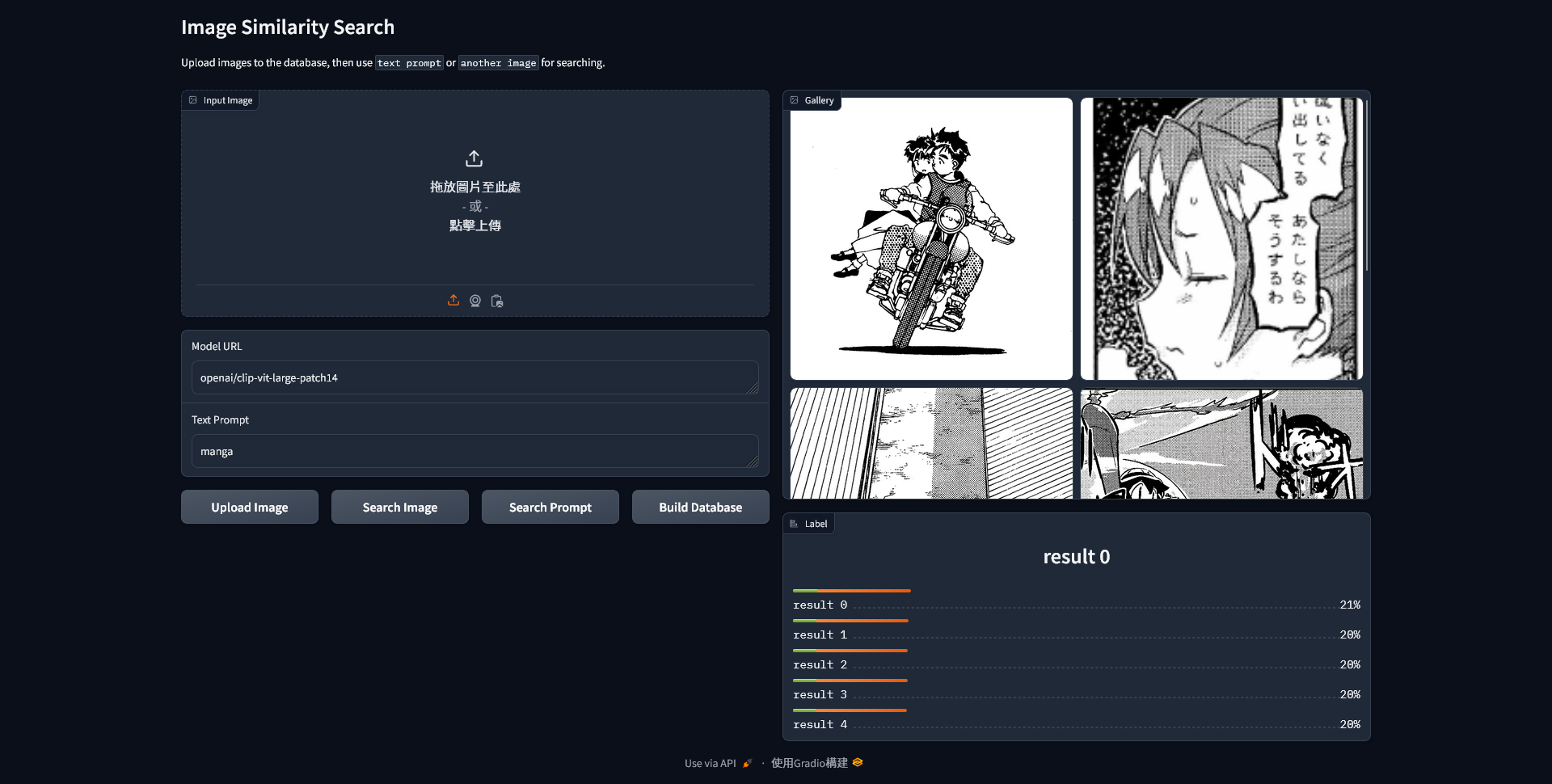
最後成果長這樣,指定文字後,搜尋宇文字相符的圖片
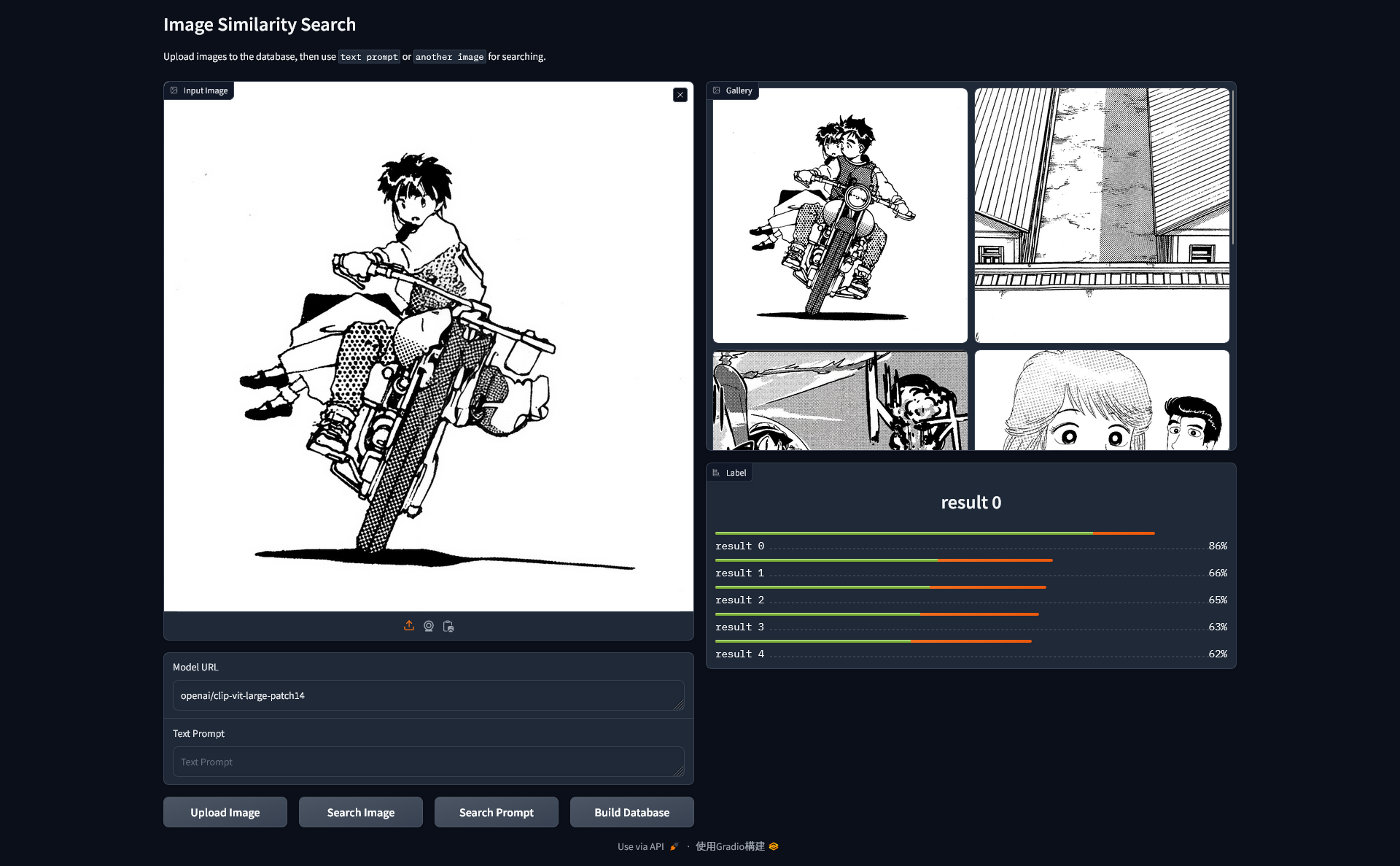
也可以上傳影像,尋找相似的圖片。
Milvus DB 簡易操作方式
環境建置
建議使用 docker compose 的方式建立
Install Milvus Standalone with Docker Compose (CPU)
連接 DB
依據 docker 的設置,連接
connections.connect(
alias="default",
user='username',
password='password',
host='URL',
port='19530'
)
Build Schema
img_path = FieldSchema(
name="img_path",
dtype=DataType.VARCHAR,
max_length=255,
is_primary=True,
)
img_emb = FieldSchema(
name="img_emb",
dtype=DataType.FLOAT_VECTOR,
dim=self.dim,
)
schema = CollectionSchema(
fields=[img_path, img_emb],
description="image search",
enable_dynamic_field=True
)
self.collection = Collection(name="image_collection", schema=schema)
插入資料
data = [
[img_path],
[img_emb]
]
res = self.collection.insert(data)
搜尋前
先連線 collection
collection = Collection(name="image_collection")
然後 build index
index_params = {
"metric_type":"COSINE",
"index_type":"IVF_FLAT",
"params":{"nlist":1024}
}
self.collection.create_index(
field_name="img_emb",
index_params=index_params
)
搜尋
搜尋前先 load,然後搜索,結束後 release,釋放資源
self.collection.load()
search_params = {"metric_type": "COSINE", "params": {"nprobe": 5}}
results = self.collection.search([embedding], "img_emb", earch_params, limit=5)
self.collection.release()
列出結果
scores = {}
res_imgs = []
result_idx = 0
for result in results:
for hit in result:
scores[f"result {result_idx}"] = hit.distance
res_imgs.append(Path(hit.id))
由於這個是在 Skywatch 實習期間做的簡易 PoC,原始碼就不公佈了。主要的難點在於要熟悉 Milvus DB 的操作方式,其餘都可以用一些現有的 library 實做出來。
留言